import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from _helpers import (
plot_incremental_metrics,
create_destandardized_model,
run_stepwise_forward_selection,
)Part 2: Segment Classification
In this tutorial, we classify individuals into pre-defined segments based on questionnaire responses, while reducing the number of questions we ask to a minimum. We use logistic regression and stepwise variable selection to identify the most informative subset of questions, and decide on an acceptable accuracy tradeoff. Ultimately, we create an optimized and efficient classification model ready for deployment via an API, enabling real-time segment prediction in production environments.
You can find the code here.
Intro
Once we have a segmentation, we want to use it to understand our customers or counterparties better. To this end, we need to assign each one to one of the segments we have identified.
The full segment assignment consists in asking all the questions used for the segmentation, normalizing the responses, calculating the distance to each segment centroid, an assigning the case to the segment with the closest centroid. However, often the cost of asking all questions used for the segmentation is too high in terms of time or churn, and so it is useful to find ways to use fewer questions to make a reasonably accurate decision on what segment to assign.
Any supervised learning algorithm can be used to make that assignment, but if you use a logistic regression, you can deploy it on diagonal.sh and use the API to make that assignment in all kinds of production settings.
Supervised learning
There are many supervised learning algorithms, but those most often used in production fall into two camps: tree based models and linear models. Tree based models excel at fitting highly nonlinear data, and nonlinear interactions between independent (“input”) variables. Linear models have the advantage of interpretability and robustness, and in many contexts similar performance to tree based models. The segmentation we want to model is based on K-Means, so we know that there can be no unexpected highly non-linear or interactive relationships in the data. This makes a linear model, and more specifically logistic regression, a good choice.
Linear models also have the advantage of being cheap to fit, which will become important for the next topic, variable selection.
Variable selection
We want to reduce the number of questions that we need to ask to identify what segment a customer belongs to. To this end, we want to rank the questions by how informative they are (of segment membership), and the expected accuracy in identifying the segment for each subset of questions we could ask. It is then up to us to make the trade-off between the number of questions and the accuracy of the resulting supervised model.
Stepwise variable selection relies on trying out the effect of adding different variables on some evaluation metric, so that, if there are N candidate variables, N! (N factorial) models need to be fit. In principle, any supervised model can be used, but linear models have the advantage of being cheap to fit, so that this process completes much faster than with other models.
Lets start again by importing our dependencies:
Set clustering columns
We use the same synthetically generated data that we used in creating the segmentation. This isn’t necessary: we could also use any other data to predict segment membership, and evaluate these by the same process.
col_to_question = {
'pyultt': 'To what extent do you prioritize unconventional thinking, even if it challenges established norms?',
'fsflss': 'How central is achieving significant financial success to your overall life plan?',
'cnslds': 'How strongly do you feel about actively working towards a society with fewer disparities?',
'ndelvn': 'How much validation do you seek from others regarding your skills and competence?',
'pepysy': 'How much do you value predictability and risk avoidance in your immediate environment?',
'ostoceny': 'How readily do you embrace significant changes and unfamiliar experiences in your life?',
'rtfrpeay': 'How much importance do you place on respecting established procedures and authority?',
'mnpetg': 'How motivated are you to genuinely grasp perspectives that differ greatly from your own?',
'pefrus': 'To what degree do you prefer to remain unobtrusive and avoid the spotlight?',
'pydyle': 'How high a priority is integrating leisure and enjoyment into your daily routine?',
'vesfdn': 'How resistant are you to external constraints on your personal choices and actions?',
'seryfros': 'How strong is your sense of personal responsibility for contributing to the well-being of others?',
'defrrdat': 'How driven are you to achieve tangible results that are publicly acknowledged?',
'pedelpsy': 'How much do you prefer decisive leadership as a means to maintain social stability?',
'rktefret': 'How willing are you to take personal risks in pursuit of stimulating or thrilling experiences?',
'aetoslee': 'How conscientious are you about adhering to social etiquette and accepted codes of conduct?',
'defrslsg': 'How significant is achieving a high social standing and being held in esteem by your peers?',
'esonrlss': 'How much emphasis do you place on steadfastness and prioritizing your commitments within close relationships?',
'cttocn': 'How deep is your personal commitment towards conservation and maintaining ecological balance?',
'veclcy': 'How much value do you place on maintaining continuity with past practices and cultural heritage?',
'iniegn': 'How inclined are you to prioritize activities that offer immediate enjoyment and gratification?'
}
clustering_cols = list(col_to_question.keys())Read data
path = "data/synthetic-value-questionnaire-segment.csv"
data = pd.read_csv(path)
data[clustering_cols + ["segment"]].head(3)| pyultt | fsflss | cnslds | ndelvn | pepysy | ostoceny | rtfrpeay | mnpetg | pefrus | pydyle | ... | defrrdat | pedelpsy | rktefret | aetoslee | defrslsg | esonrlss | cttocn | veclcy | iniegn | segment | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 1 | 5 | 1 | 2 | 4 | 1 | 5 | 5 | 5 | ... | 1 | 1 | 2 | 1 | 2 | 4 | 5 | 2 | 3 | 1 |
| 1 | 2 | 3 | 5 | 2 | 3 | 5 | 1 | 4 | 5 | 3 | ... | 3 | 2 | 3 | 4 | 3 | 1 | 4 | 3 | 2 | 1 |
| 2 | 2 | 4 | 6 | 5 | 5 | 3 | 6 | 4 | 5 | 4 | ... | 5 | 5 | 3 | 6 | 5 | 5 | 5 | 5 | 2 | 0 |
3 rows × 22 columns
Standardize data across columns to facilitate training
In the segmentation, we added row-wise normalisation, to filter out any “agreement bias”, where some respondents just agree to most questions. When identifying groups in data, the trade-offs a person makes are the most interesting aspect, and this is reflected in this preprocessing step.
For the classification step, we might want to feed in the responses directly into the model, which precludes row-wise normalization. However, we can normalise each variable, i.e. column-wise, to aid convergence in training, and then reverse that normalisation through denormalisation. In this way, we get the training benefits while still having a model that can be fed with raw response values.
clustering_col_means = data[clustering_cols].values.mean(0)
clustering_cols_stdevs = data[clustering_cols].values.std(0)
clustering_cols_standardized = [f"{col}_standardized" for col in clustering_cols]
data[clustering_cols_standardized] = (
data[clustering_cols].values
- np.tile(clustering_col_means, data.shape[0]).reshape(
data.shape[0], len(clustering_cols)
)
) / np.tile(clustering_cols_stdevs, data.shape[0]).reshape(
data.shape[0], len(clustering_cols)
)Run stepwise forward variable selection
There are several ways of implementing variable selection, but here we will go with forward variable selection. The idea is simple enough: we try adding each candidate predictive variable, fit a model, look at some validation metric, and pick the best one according to that metric. The selected candidate variable is added to the set of selected variables and removed from the set of candidate variables. In the next iteration, each of the remaining candidate variables is added separately to the selected variables to evaluate the marginal improvement on the evaluation metric, and the best one is added. This is repeated until the last candidate variable has been added.
column_recall_increment = run_stepwise_forward_selection(
data[clustering_cols_standardized],
data["segment"].values,
clustering_cols_standardized,
col_to_question,
)How much do you prefer decisive leadership as a means to maintain social stability?: 0.541
How central is achieving significant financial success to your overall life plan?: 0.640
How readily do you embrace significant changes and unfamiliar experiences in your life?: 0.703
How strong is your sense of personal responsibility for contributing to the well-being of others?: 0.744
How much validation do you seek from others regarding your skills and competence?: 0.779
How conscientious are you about adhering to social etiquette and accepted codes of conduct?: 0.804
How strongly do you feel about actively working towards a society with fewer disparities?: 0.828
How much do you value predictability and risk avoidance in your immediate environment?: 0.847
How resistant are you to external constraints on your personal choices and actions?: 0.858
How inclined are you to prioritize activities that offer immediate enjoyment and gratification?: 0.872
How motivated are you to genuinely grasp perspectives that differ greatly from your own?: 0.887
How deep is your personal commitment towards conservation and maintaining ecological balance?: 0.898
How significant is achieving a high social standing and being held in esteem by your peers?: 0.911
How much importance do you place on respecting established procedures and authority?: 0.923
To what degree do you prefer to remain unobtrusive and avoid the spotlight?: 0.929
How driven are you to achieve tangible results that are publicly acknowledged?: 0.937
To what extent do you prioritize unconventional thinking, even if it challenges established norms?: 0.946
How much value do you place on maintaining continuity with past practices and cultural heritage?: 0.959
How much emphasis do you place on steadfastness and prioritizing your commitments within close relationships?: 0.966
How high a priority is integrating leisure and enjoyment into your daily routine?: 0.975
How willing are you to take personal risks in pursuit of stimulating or thrilling experiences?: 1.000Plot model performance as variables are added
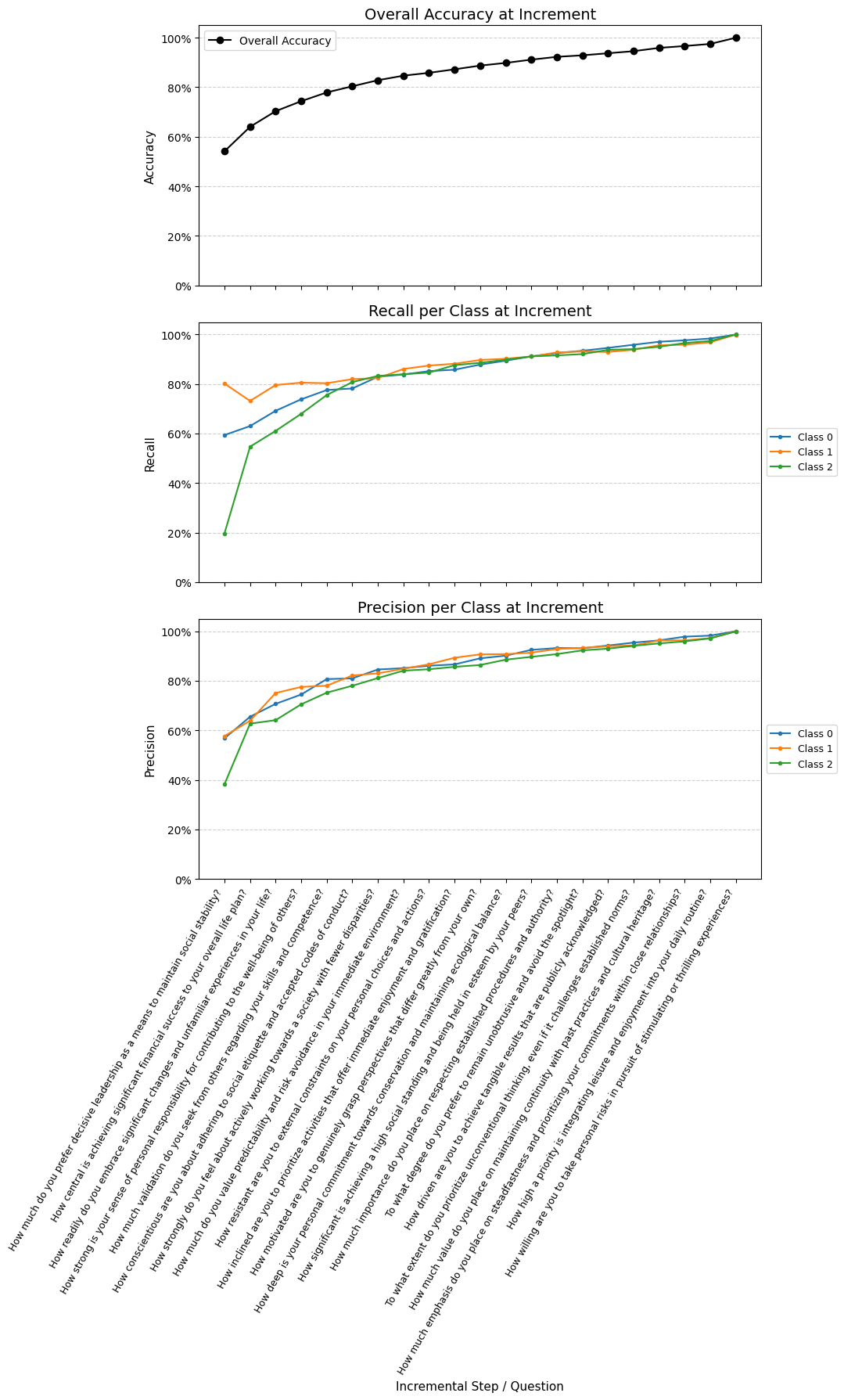
We will have to make a decision as to how many questions we want to ask for the purpose of segment identification, and make the trade-off between the number of questions asked (which is expensive) and the accuracy of the segment attribution. This decision can be made more easily if the accuracy achieved for a given number of variables is visualised, for the data as a whole and for each subclass.
plot_incremental_metrics(
{
col_to_question[col.replace("_standardized", "")]: val
for col, val in column_recall_increment.items()
}
)
Pick the number of variables and train model
At 7 variables, the recall and precision for each segment is above 80%. This will be sufficient for our (hypothetical) use-case, and so we set n_selected_cols to that value, and fit the predictive model. We predict the target values from the data with the model, to use to validate the denormalization.
n_selected_cols = 7
selected_cols = list(column_recall_increment.keys())[:n_selected_cols]
print([col_to_question[col.replace("_standardized", "")] for col in selected_cols])
clf = LogisticRegression(penalty=None, fit_intercept=True)
clf.fit(data[selected_cols].values, data["segment"])
y_hat = clf.predict(data[selected_cols])['How much do you prefer decisive leadership as a means to maintain social stability?', 'How central is achieving significant financial success to your overall life plan?', 'How readily do you embrace significant changes and unfamiliar experiences in your life?', 'How strong is your sense of personal responsibility for contributing to the well-being of others?', 'How much validation do you seek from others regarding your skills and competence?', 'How conscientious are you about adhering to social etiquette and accepted codes of conduct?', 'How strongly do you feel about actively working towards a society with fewer disparities?']/Users/diagonal.sh/miniconda3/envs/tutorial/lib/python3.12/site-packages/sklearn/utils/validation.py:2732: UserWarning: X has feature names, but LogisticRegression was fitted without feature names
warnings.warn(These are the selected questions:
How much do you prefer decisive leadership as a means to maintain social stability?
How central is achieving significant financial success to your overall life plan?
How readily do you embrace significant changes and unfamiliar experiences in your life?
How strong is your sense of personal responsibility for contributing to the well-being of others?
How much validation do you seek from others regarding your skills and competence?
How conscientious are you about adhering to social etiquette and accepted codes of conduct?
How strongly do you feel about actively working towards a society with fewer disparities?
Denormalize model coefficients to work with raw questionnaire input
Since we want to pass the raw response data to the model, we need to denormalize the coefficients. This transforms a model that is adapted to the normalised data used for training to one that can take raw inputs. We need to pass the non-standardised data, the target segments, the coefficients, and the normalisation parameters (i.e. mean and standard deviation for each “raw” variable). We also pass y_hat to validate that the denormalisation does not change the output for any of the cases.
### select original column means and standard deviations in selected order
clustering_col_means_selected = [
clustering_col_means[
np.argmax(np.array(clustering_cols) == col.replace("_standardized", ""))
]
for col in selected_cols
]
clustering_cols_stdevs_selected = [
clustering_cols_stdevs[
np.argmax(np.array(clustering_cols) == col.replace("_standardized", ""))
]
for col in selected_cols
]
### create destandardized model
clf_destandardized = create_destandardized_model(
data[[col.replace("_standardized", "") for col in selected_cols]].values,
data["segment"].values,
clf.coef_,
clf.intercept_,
clustering_col_means_selected,
clustering_cols_stdevs_selected,
y_hat,
)Success! Denormalization has preserved the mapping: np.mean(y_hat_destandardized == y_hat_baseline) = np.float64(1.0)Export model to diagonal.sh
In our example, we might want to ask different questions to members of different segments in an online questionnaire. This requires some way of running the classification model to determine the segment of each respondent, and the simplest and cheapest way of doing this is diagonal.sh.
To use this, you need to install diagonalpy, open an account, and generate a “Console API key”. You then need to set the env variable DIAGONALSH_API_KEY to that key (or set it in this notebook).
import os
from diagonalpy.export import export
os.environ["DIAGONALSH_API_KEY"] = os.getenv("DIAGONALSH_API_KEY")
os.environ["DIAGONALSH_REGION"] = "eu-west-3"
export(clf_destandardized, "my-beautiful-classifier")Conversion succeeded at tolerance 1.0e-10 on output probabilities{'filename': 'my-beautiful-classifier.onnx',
'status': 'success',
'model_id': 'eccbc3a4-0b05-4c90-a599-a55b0e160946',
'model_route': 'i4t90dQu-7YUTwuMn-B15SDcnr'}… wait for 15 minutes ⏰
Now your model is available on the web 🌈 (only with the correct auth token 🔒)
For the deployment to proceed, you need to have created an “Inference API key”, which you then use to authenticate your request.
You can query it like this:
curl -X POST “https://infer.diagonal.sh/i4t90dQu-7YUTwuMn-B15SDcnr”
-H “Content-Type: application/json”
-H “X-API-Key: ABCDEFGHIJKLMNOPQRSTUVWXYZ”
-d ‘{“data”: [3, 2, 1, 3, 2, 5, 3], “model”: “eccbc3a4-0b05-4c90-a599-a55b0e160946”}’
And you get back:
{“message”: 2}
i.e., these responses indicate the respondent belongs to segment 2, “communitarian”